STROBE声明:观察性研究报告规范
虽然观察性研究在循证医学中的等级不如随机对照研究(RCT),但很多临床问题(如病因、诊断、预后等)需要依靠观察性研究才能获得结论,因此,在设计中,我们临床研究最常用到的还是观察性研究。便于写作时有章可循,本期的主题是解析观察性研究报告规范,即STROBE声明。
《加强观察性流行病学研究报告声明》
STROBE Statement
(Strengthening the Reporting of Observational Studies in Epidemiology)
详细信息见:www.strobe-statement.org

相比于CONSORT规范,STROBE声明较晚,并借鉴了它的经验。不同之处在于:STROBE不仅针对一种研究方案,而是用于横断面研究、病例-对照研究和队列研究三种观察性研究及其各种衍生的研究设计方案。因此,在STROBE官网上,我们既能看到通用的清单,也有3种研究设计各自的清单。
STROBE的来源
- 1.2004年9月,流行病学家、方法学家、统计学家、7名著名杂志的编辑及少数医生,在英国Bristol大学召开的国际会议上,讨论并制定了STROBE清单第1版;
- 2.2005年4月由方法学家、研究者和编辑组成的STROBE工作小组制定了STROBE清单第2版;
- 3.2005年9月制定了STROBE清单第3版;
- 4.2007年10月制定了STROBE清单第4版;
- 5.2014年在LancetInfectious Diseases上发表了STROBE扩展版本STROBE-ID (Strengthening the Reporting of Observational Studies in Epidemiology for Infectious Diseases),主要针对感染性疾病,在STROBE基础上又加入了20个条目。
STROBE(第4版)的内容
1.自查清单:
STROBE对文章各部分做了规范,包括“题目和摘要”、“引言”、“方法部分”、“结果部分”、“讨论部分”和“其它信息”六大部分。共列出了22个条目的清单和要求,并且对各部分规定了排序。你可以使用以下表单进行文章发表时的自查。
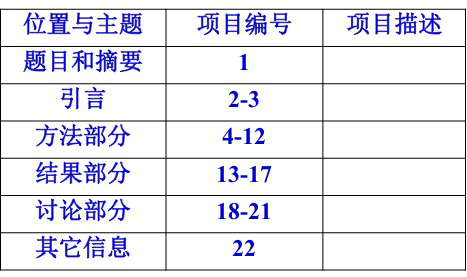
注意:其中18个条目对三种观察性研究设计是共用的,4个条目(条目6、12、14和15)根据研究设计而异,用于队列研究、病例-对照研究或横断面研究某种特定的设计类型。
2.STROBE内容解析
我们重点对“方法部分”和“结果部分”做详细解析。
STROBE清单的“方法部分”

Item4 研究设计
尽早陈述研究设计的关键内容:
在方法学的前期(或者在前言末尾)写明研究设计要素,使读者能理解整个研究的基础。例如:
- 1)报告队列研究时,应用专门的术语“队列研究”说明研究的性质,描述组成队列的人群和他们的暴露状况;
- 2)病例对照研究,应描述病例和对照及其源人群;
- 3)横断面调查,应描述人群和重要时间点。
Item 5 研究设置
描述研究现场、具体场所及相关资料(包括招募的时间范围、暴露、随访和数据收集时间等):
- 1)研究现场:研究对象征集地或来源(如选民名册、门诊登记、癌症登记,或三级医疗中心);
- 2)研究具体场所:国家、城镇及医院等调查发生地;
- 3)时间范围:写明具体时间而不仅仅描述持续时期。
Item 6 研究对象
描述选择研究对象的合格标准(即纳入和排除标准)、源人群 (如一个国家或地区的一般人群) 和研究对象征集方法(如志愿者);
2)如果使用了匹配设计,应描述选择匹配变量的原理和方法细节,例如:
- 队列研究需描述配对标准和暴露与非暴露数目;
- 病例对照研究需描述配对标准、方式(频数匹配或个体匹配)和每个病例对应的对照数目。
Item 7 研究变量
1)明确定义结局、暴露、预测因子、潜在的混杂因子和效应修正因子(如有可能,给出诊断标准);
2)不要用“自变量” 或“原因变量”描述暴露和混杂变量,因为它不能从混杂因子中区分暴露。
3)如果在探索性分析中使用了很多变量,要在附录、附表或独立发表的文章中对每一个变量列一个详细清单;
阐明统计分析的 “备选变量”,而不是仅选择地报告包含在最终模型里的变量。
Item 8 数据来源和测量
1)对每个有关心的变量,描述其数据来源和详细的测量方法,如果有多组,还应描述各组之间测量方法的可比性;
2)暴露、混杂因素和结局的测量方法可影响研究的效度和信度。如:暴露或结局的错误分类可能产生虚假联系。因此,建议报告研究的信度或效度的评价或测量结果,包括参考标准的细节问题,这可用来校正测量误差或对测量误差进行敏感度分析;
3)比较组间数据收集方法是否有差别也很重要。
Item 9 偏倚
1)在设计阶段,思考偏倚的可能来源,在报告阶段,估计相关偏倚的可能性。特别应讨论偏倚的方向和大小,可能的话,计算偏倚值。
2)提供更多处理偏倚的细节,描述质量控制计划(如数据收集质量控制计划,调查员的培训等),保证变量变异最小。
Item 10 样本量
1)样本量的计算依赖于研究背景;
2)研究必须有足够的样本量以得到一个精度较高的置信区间(充分狭窄)估计参数;
3)应指明样本量的确定方法。
Item 11 定量变量
解释分析中如何处理计算变量,如有可能,描述如何选择分组及分组原因。
Item 12 统计方法
1)描述所有统计方法,包括控制混杂的方法;
2)描述亚组和交互作用的检查方法;
3)描述缺失值的处理方法;
4)队列研究中报告失访数和对待截尾数据的策略;病例-对照研究的分层分析和logistic回归;横断面研究根据抽样策略确定的统计学方法等;
5)描述敏感度分析,检验主要结果是否与其他分析策略或假设条件下的结果一致。
STROBE清单的“结果部分”清单详见下表,主要包括:研究对象、描述性资料、结局资料、主要结果和其他分析等条目。下面,我们就对每个条目做详细解析。
STROBE清单的“结果部分”

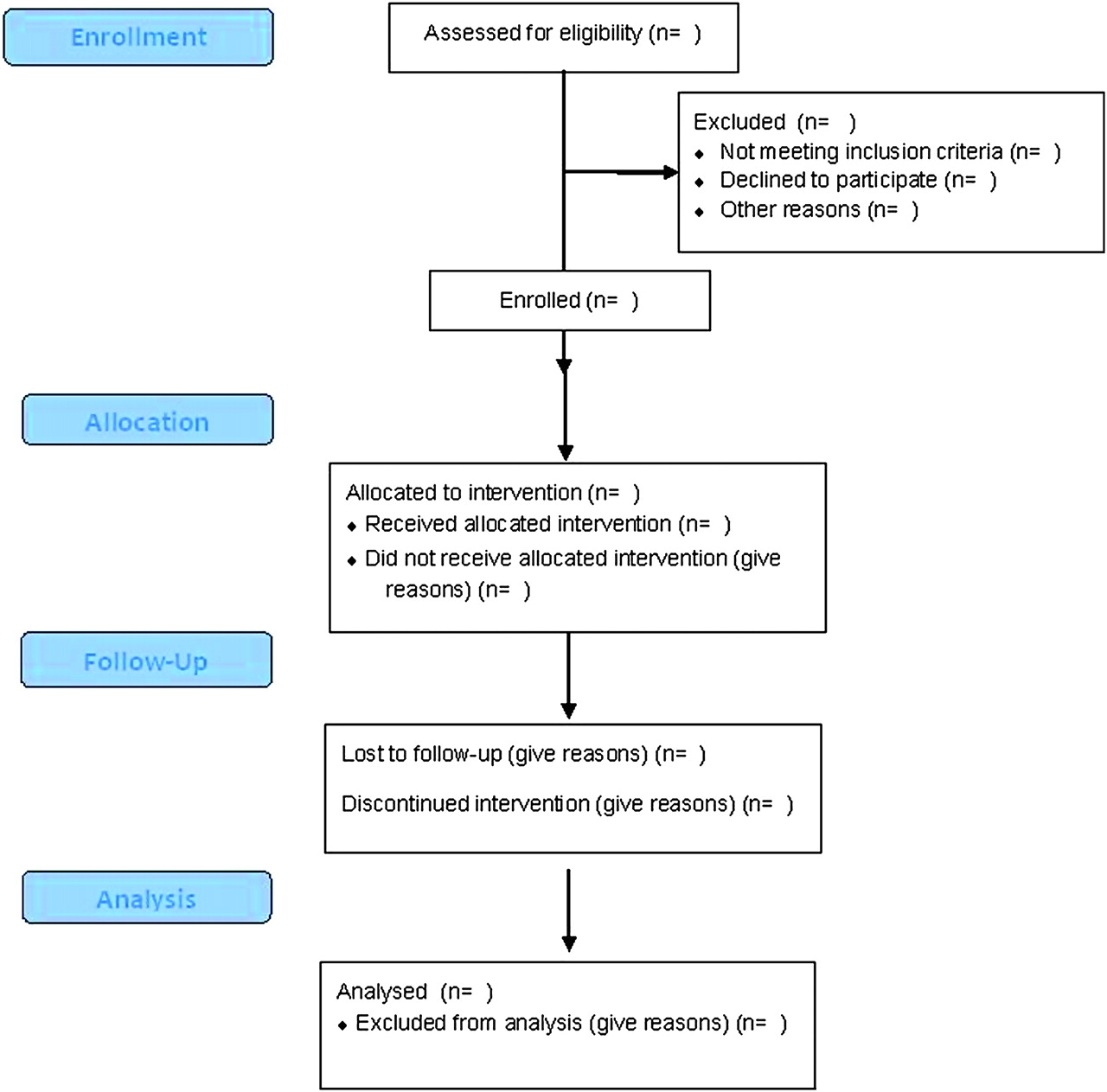
Item 13 研究对象
1)报告研究各个阶段研究对象的数量,要尽量详细。
因为进入研究的人可能不同于研究结果适用的目标人群,导致患病率或发病率的估计值不能反映目标人群的水平;
例如:母亲生育年龄小和后代患白血病之间的关联,部分原因是有健康孩子的年轻母亲会比有不健康孩子的年轻母亲更少参加这种调查研究。
2)描述各阶段研究对象未能参与的原因,以便读者判断研究人群是否代表目标人群,是否会产生偏倚,例如:
横断面调查中,所选对象由于与健康无关的原因而不参加研究(如征集信函由于错误的地址而没有邮寄到)会影响估计的精度,但却可能不会产生偏倚。
建议使用流程图,例如:
Item 14 描述性资料
- 描述研究对象的特征(如人口学、临床和社会特征)以及关于暴露和潜在混杂因素的信息以及关于暴露和潜在混杂因子的信息;
- 指出每个关心的变量有缺失值的研究对象数目、暴露、潜在混杂因子和患者的其他重要特征,不同程度和原因的失访;
- 队列研究总结随访时间,报告随访期限的最大值和最小值或总体分布的百分位数,总随访人年,所获得潜在数据的一些比例指标。
Item 15 结局资料
1)报告发生结局事件(队列研究、横断面研究)或暴露类别(病例-对照研究)的数量;
2)或根据时间总结发生结局事件的数量。
Item 16 主要结果
1)给出未校正的和校正的混杂因素的关联强度估计值、精确度(如95%CI);
- 阐明根据哪些混杂因素进行了调整以及选择这些因素的原因;
2)当对连续性变量分组时,报告分组界值;
3)如有关联,可将有意义时期内的相对危险度转化成绝对危险度。
Item 17 其他分析
亚组分析:
- 分辨几个合适分类的亚组分别分析的关联与总体关联是否一致;
- 介绍在数据分析过程中出现的感兴趣的亚组,需报告准备进行哪些分析,没有准备的哪些分析;
2)交互作用分析:
- 应同时报告每种暴露各自的效果和他们之间的联合作用及置信区间;
3)敏感性分析:
- 有助于估计在缺失数据或可能的偏倚下得到的研究结果是否可靠;
- 如果所分析的问题很受关注,或者效应估计值变化很大时需要详细说明。
